

A Content Based Movie Recommender using Kaggle
Recommendation Systems are used in almost every form of available online entertainment platforms such as Youtube, Netflix, Spotify, etc. The main aim is to enhance user experience by providing them better suggestions based on their activity, the content viewed by them, the similar content viewed by other people, etc. As a part of this project I have tried to create a basic version of a Content-Based Movie Recommendation System using TMDB 5000 Movie Dataset available on Kaggle that contains metadata of around 4800 unique movies including movie overview, genre, cast and crew, ratings, votes, turnover, language, etc.
Kaggle as a Digital Tool
Over the past few years, as the scope of Machine Learning and Artificial Intelligence grew, Kaggle has become a leading platform for collaboration of Data Scientists, whether beginners or researchers. The Kaggle community hosts several free datasets in various fields, algorithms, code snippets, competitions involving real life problems, etc. Launched by Google in 2010, Kaggle allows users to explore anything related to Data Science and its applications, also proving to be a great online learning platform for free.
{kind=link}
-data-science-competitions-1-638.jpg?cb=1488906029
Currently, all online entertainment platforms collect data from their users to form user analytics and enhance the user experience quality. The type of content we stream is often what is recommended to us. This is no magic, but a recommendation system collecting data from millions of users and providing results based on demographics of the user, of the content viewed by them, etc. Such recommendations further develop our taste and preference, and the dynamic process continues. There is a recommendation system for every type of such big data where user taste matters! The type of news in our feed, the posts on Instagram, Spotify and Netflix recommendations, etc are all the result of Machine Learning processes.
In this project I have created a simple recommendation system for a popular ‘The Movie Database (TMDb)’ of around 4800 movies. The dataset is hosted by Kaggle. Also, the tutorial followed for the project is hosted by Kaggle.
Algorithm Overview
I have implemented a Content Based Recommendation System.
In this type of the recommender system, the type of content of the movie is used to find other similar movies. For example if a viewer watches a romance movie, he/she will be recommended movies of the ‘romance’ genre. If the movie has romance and comedy as the genr, the recommendations will be modified accordingly. If a viewer likes to watch movies of Leonardo DiCaprio, he/she will often be recommended movies of the same actor. A pictorial representation of the system is as follows:
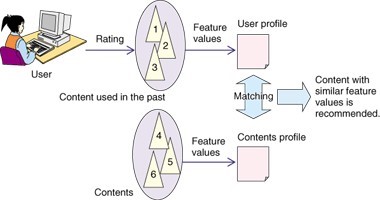
https://www.ntt-review.jp/archive_html/200804/images/le1_fig02.gi
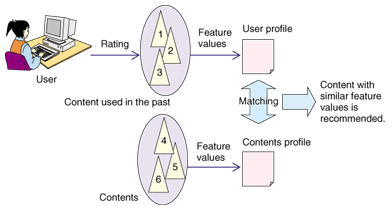{kind=link}
1) Data Cleaning and Modifying
Data Cleaning refers to removing unhelpful content from a given data. For example, while extracting relevant words from a movies overview, we must ignore articles, pronouns, conjunctions, connector words and other such words which do not provide useful information. This is performed by the feature ‘stop word’ of the sklearn library in Python specifically used for Natural Language Processing applications.
Data modifying refers to extracting and adjusting the given array in an instance like list, dictionary or tuple according to our requirements and stripping off other unnecessary labels.
2) TFDIF Vectorizer
TFDIF stands for ‘Term Frequency Inverse Document Frequency’ is a feature to compute the importance of a given data in a similar bulk of data. The importance is represented as a normalized numerical quantity. More the number of occurrences of a given data, higher its TFIDF value. Thus, this statistical feature is applied to the overview of the movies. Relevant and useful words in the overview list are assigned a numerical weight based upon the total available data and the frequency of their occurence.
Apart from this method, we also have a Count vectorizer available that does not normalise the result, thus not decreasing the worth of each feature!
3) Cosine Similarity
The cosine similarity approach measures the similarity between two given values. If they are similar, the algorithm results in a higher value of output. In our recommender system, we are using this algorithm to measure the similarity between overviews of the movie whose recommendations are to be generated along with other movies in the dataset based upon the TFDIF calculated previously. The cosine similarity formula is given as follows:
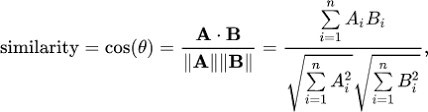
In the initial phase of the project, only the overview of movies is used to generate the recommendations. Later this has been extended to involve the genre and other movie features also.
The entire project has been implemented on Google Colab, that allows to execute Python Code along with sharing online. The viewing link for the same commented code is as follows:
Content based Movie Recommender System
Results
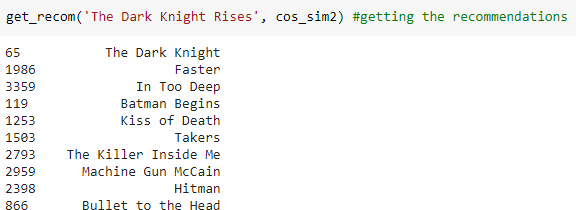
Some of the interesting results generated by the recommendation system are as follows
1)

Using the overview of movies
Using the genre and other features of movies
Scope of Improvement
The recommendation system can be improved by adding more movies in the list along with taking more features for generating the recommendations. We can combine the Content-based filtering along with Collaborative filtering, in which other users also play a role in generating recommendations.
Correspondence with Digital Cultures
As part of the project I have tried to illustrate a small use of the multi-featured free tool Kaggle, which can be used in various domains pertaining to Data Science and its development. Also, the topic chosen for the project is a prototype of widely used complex algorithms to generate recommendations Our data is collected and interpreted at various levels for various purposes. Further, our large viewership develops demand for a certain type of content, which is taken note of by the creators. Such backend algorithms determine the development of digital content and culture at a large scale.
References
https://www.kaggle.com/tmdb/tmdb-movie-metadata https://www.kaggle.com/ibtesama/getting-started-with-a-movie-recommendation-syst em/data
Recent Comments